Antlr4 polynomial grammar - 2020 update
Antlr4
A few years back I was playing with Antlr to build a polynomial evaluator. The result was working but not very sofisticated o particularly good, just a minimal working example. In these days of quarantine in Italy, I decided to get back a that project and try to make something better. The final result can be found at this repo.
Just quick remainder on what is Antlr:
Antlr4 is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It's widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees.
The getting started guide it's almost everything you need in order to make it work. A very useful guide is the one written by Tomassetti at The ANTLR mega tutorial.
Polynomial model
In order to properly parse and evaluate a polynomial, we have to represent it first in a convenient way. I want to be able to represent polynomial with multiple variables. I went for a simple tree like data structure with different type of nodes:
- AddNode
- PowerNode
- ProductNode
- SubtractNode
- VariableNode
This is how we will represent in memory a simple polynomial:
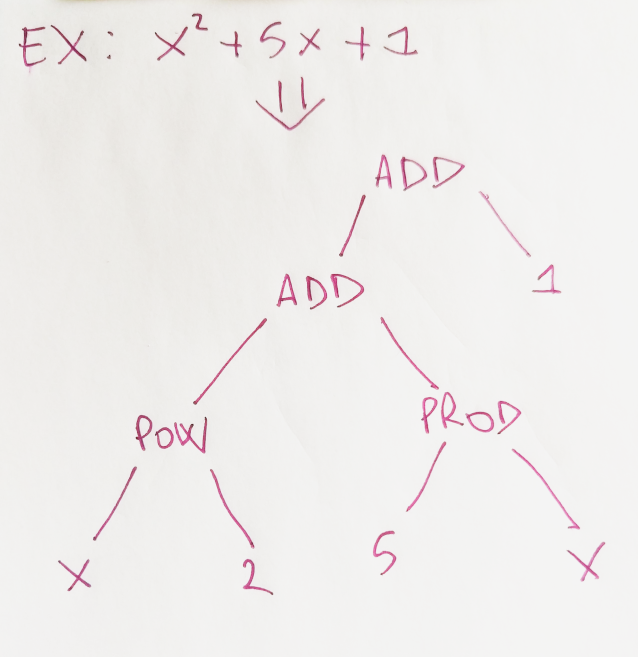
Each node has an eval method that accepts a Dictionary<char,double>, one value for each variable in the polynomial. Let's see the INode interface and the AddNode class
In a similar way I defined the other node types. It's easy but cumbersome to use the nodes type to manually build the polynomial x^2+5x+1 from the example
var p = new AddNode(AddNode(PowerNode(new VariableNode(x),new ConstNode(2)),ProductNode(new ConstNode(5),new VariableNode(x))),new ConstNode(1));
Luckily for us we will not be doing anything like that because we will use ANTLR to build for us the polynomial representation from the string x^2+5x+1. Now let's look at the grammar definition
grammar Polynomial;
expr : OP expr CP #parenExp
| <assoc=right> expr POWER expr #power
| expr PROD? expr #prod
| expr (PLUS|MINUS) expr #plusminus
| VAR #var
| NUM #const;
CP : ')';
OP : '(';
PLUS : '+';
MINUS : '-';
PROD : '*';
POWER : '^';
NUM : [0-9.]+;
VAR : [a-z];
WS : ' ' -> skip;
I'm absolutely no expert for what concerns ANTLR, parser and grammars so please take all that follows with a grain of salt. The structure of the file is something like [Id] : [matching rule];, the lines with UPPERCASE identifiers are the tokens, ANTLR will read the text and recognize all the tokens and then use them to build the tree. Eg:
| Text | Tokens |
|---|---|
| x^2 | VAR POWER NUM |
| x+1 | VAR PLUS NUM |
| (x-2) | OP VAR MINUS CP |
The lines with lowercase identifiers are the parser rules, we have one rule expr with several cases. The #[text] at the end of each line is an alias for that case and it will be useful while implementing the visitor since for each label ANTLR will generate a specific Visit method, such as VisitVar and VisitConst.
Starting from the bottom:
- const : this rule will recognize a number such as
1or2or1.5 - var : this rule will recognize a variable such as
x,yorz - plusminus : this rule is slightly more complex since it is recursive,
exprcould be any of the other cases, listed below or above. It is going to matchexpr PLUS exprsuch asx+yorx+1expr MINUS exprsuch asx-5
- prod : this rule will recognize
xyorx*yor5x - power: this rule has
<assoc=right>at the beginning, what's the difference with the other rules? That modifier is required because ANTLR is left associative by default, ie it builds the tree consideringx+y+z = (x+y)+z. Exponentiation however is right associative, iex^y^z= x^(y^z), so we need to tell ANTLR that. The rule will recognizex^y^zorx^5. - parentExp: this rule will recognize
(x),(x+1)and such.
Of course all the recursive rules, for each instance of expr can contains any of the other cases or combination of them. Referring to the repo, running the gen.bat will create all the required files to run ANTLR and a base visitor class since I used the -visitor flag. Thanks to the labels, the base visitor class has a method for each different expr case and for each one we need to build the correct node. The implementation is very simple:
There are several tests to show that the implementation is correct and to show what is possible using the grammar and the evaluator. In the end we can also parse something like (x+1)^(y-2), nice uh? All of this is possible thanks to ANTLR! Give it a try and let me know what you think! How can we expand the evaluator?